Wayback Machine(ウェイバックマシン)とは?使い方から基本知識までを解説

過去に公開されていたあのサイトが見たい!間違って削除してしまったブログの記事を復活させたい!と考えた経験のあるかたも多いと思います。
この記事では、そうした希望に役に立つWayback Machine(ウェイバックマシン)というツールサービスを紹介します。
基本的な使い方から応用的な使い方、競合サイトの調査といった活用方法まで詳しく解説していますので是非参考にしてみてください!
まずは、Wayback Machineがなんなのか?といった所から解説を始めていきます。
無料で簡単インストール。
オープンソースのメールフォームCMS
「EasyMail(イージーメール)」を使ってみませんか?
改変でも、再配布でも、商用利用でも、有料販売でも、
自由に無料でつかうことができるメールフォーム!
目次
- 1 Wayback Machine(ウェイバックマシン)とは?特徴
- 2 Wayback Machineのデータ保存数の確認方法
- 3 Wayback Machine(ウェイバックマシン)の使い方(基本編)
- 4 Wayback Machine(ウェイバックマシン)の使い方(応用編)
- 5 Wayback Machine(ウェイバックマシン)の活用方法
- 6 Wayback Machineの安全性
- 7 Wayback MachineでTwitterのタイムラインやYouTubeの動画は保存できる?
- 8 Wayback Machineの注意点
- 9 Wayback Machineでサイトや動画・画像が見られない!原因は?
- 10 Wayback Machineとは?まとめ
Wayback Machine(ウェイバックマシン)とは?特徴
Wayback Machineはシンプルに説明すると、“過去ページ(log)を閲覧&保存できる無料ツールサービス”です。
なぜこんなに便利なサービスが無料で使えるのかと言うと、Wayback Machineの運営資金は寄付でまかなわれているため、ユーザーは無料で使用できるのです。
運営元のInternet Archiveは、アメリカのサンフランシスコで1996年に発足した非営利団体で、WEBサイトのトラフィック情報を独自に収集するAlexa Internetの協力を得ながら、インターネット上にある莫大なデータをクローリングしてデータベースに保存しています。
保存しているデータは約6,400億ページ以上あり、WEBサイトだけでなく、Twitterや書籍、音楽、映画などといったデータも保存されています。
Wayback Machineには以下のURLからアクセスできます。
Wayback Machineのメリット
Wayback Machineのメリットは以下になります。
- 無料で使える
- 現在・過去のサイト比較
- サイトやドメインの歴史を調べられる
- 自分の過去サイトや記事を確認できる
- 競合サイトの過去はどのようなものだったか?分析に使える
無料で使える
Wayback Machineの最大のメリットはなんといっても、無料で使用できる点です。
インターネットには無数のサイトや記事がありますが、それらすべてを保存してくれるのに無料で使えるのはとてもありがたいですよね。
ただし自動保存だと保存しきれない瞬間も出てきますので、絶対に保存しておきたいページなどがあれば、手動保存しておくと安心です。
現在・過去のサイト比較
Wayback Machineを利用すると、現在と過去のサイトを比較できます。
例えば、リニューアル後などにサイトのアクセス数や回遊率が下がった時に、過去と現在のサイトにはどのような違いがあったのかなどを比較する場合に役立ちます。
特にWayback Machineでは、画像やリンクも当時の状態のまま見られるので、実際に過去のサイトの状態を触ってみてどのような違いがあるのか比較しやすいでしょう。
サイトやドメインの歴史を調べられる
Wayback Machineを使うと、サイトがどのように成長していったのかなどサイトの歴史を調べられます。
自分が運営している以外のサイトの歴史を見られるのは、サイトを運用する人にとって大きなヒントになりえるでしょう。
またドメインの歴史も調べられるので、中古ドメインを検討している人などは、検討している中古ドメインで過去に運営されていたサイトはどのようなものだったか?といった情報を調べられます。
中古ドメインは、ドメインパワーが大きくSEOにも有利と言われています。
しかし検討しているドメインが過去に良くないサイトを運営していた場合は逆効果にもなりかねないので、過去に運営していたサイト情報はとても重要です。
このような理由から、中古ドメインを検討している人は特にWayback Machineを利用してみると良いでしょう。
自分の過去サイトや記事を確認できる
これまでどのようなサイトの歴史を築いてきたのか、作成したサイトの歴史をWayback Machineを使えば簡単に確認できます。
サイト作成後、運営始めたての頃は「こういったサイトにしたい」というような目標がありましたよね。
目標に近づけているのかなどを確認することも、Wayback Machineを使えば可能です。
サイト設立から今に至るまでの歴史を確認することでサイトをいっそう盛り上げるヒントも得られますから、サイト運営をするなら持っておきたいツールの一つと言えるでしょう。
競合サイトの過去はどのようなものだったか?分析に使える
競合サイトはどのような歴史を築いてきたのかも、Wayback Machineを使うと確認できます。
現在大きくなっているサイトは、最初どのようなカテゴリーがあってどのようなデザインだったのか、どのようにサイトを改善していったのかなどを見られるのは強いですね。
良いサイトを築くために、他サイト分析は欠かせません。
より良い運営を目指すためにWayback Machineを活用しましょう。
Wayback Machineのデータ保存数の確認方法
Wayback Machineの中に、対象URL・キーワードに対するデータがどれくらい保存されているのか確認できます。
結果が表示されると、画面内に「Saved 〇〇times between 〇〇 and 〇〇」と表示がありますが、この部分がデータの保存数です。
以下の画像を参考にすると
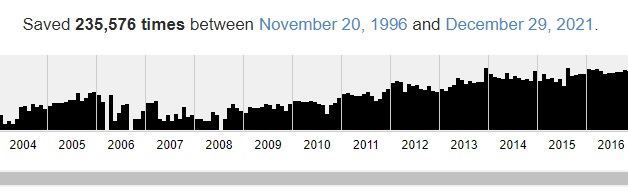
「Saved 235,576 times between November 20, 1996 and December 29, 2021.」と書かれていますね。
つまりこれは、「1996年11月20日から2021年12月29日の間に 235,576のアーカイブデータを保存している」という意味です。
今回はYahoo!のサイトを調べたのですが、こうした大規模なWEBサイトの場合でも、Wayback Machineは膨大なアーカイブデータを保存し、無料で簡単に閲覧できます。
Wayback Machine(ウェイバックマシン)の使い方(基本編)

それでは実際にWayback Machineの使い方について解説します。
使い方は非常に簡単です。
ただ色々な使い方のパターンがあるので、ここでは主に「2つの方法で検索するパターン」と「検索結果から過去のWEBサイトを閲覧する方法」について図を使って説明します。
URLから検索する

Wayback Machineのサイトにアクセスして検索窓に調べたいURLを入れます。
入力後に、検索窓の横にある「BROWSE HISTORY」というボタンをクリックしましょう。
この入力するURLはサイトのTOPページのURLだけでなく、記事単位でのURLでも問題ありません。
調べたいページが特定されている場合はページを指定してURLを入れてあげるとよいでしょう。
大規模サイトのTOPページURLだと結果が表示されるまでに時間がかかる場合があります。
キーワードから検索する

Wayback Machineのサイトにアクセスして検索窓に調べたいキーワードを入れます。
すると、キーワードに関連するサイトの一覧が表示されるので、一覧に表示されたサイトのURLかサイトのサムネイルをクリックすると選択したサイトの情報を見られます。
検索窓に入力するキーワードは「野球」のような単ワードだけでなく「野球 試合結果」のように掛け合わたキーワードでも検索可能です。
過去のWEBサイトを見る
結果が表示された後に過去のWEBサイトを閲覧する方法について解説します。
今回は使用する機会が多いと思われるURLから、検索したあとの流れについて解説します。
まず、上記で説明したように検索窓に調べたいサイトのURLを入力します。
すると以下画像のような年度毎の棒グラフが表示されるので、調べたい年を選択しましょう。
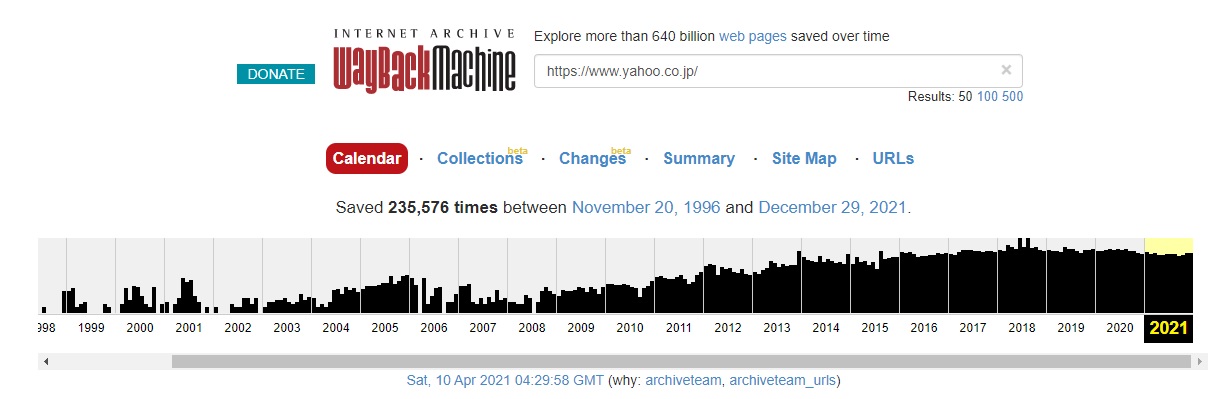
次に、調べたい年を選択すると、その年のカレンダーが表示されます。色付きの丸い円がある日付がアーカイブデータがある日付なので、調べたい日付を選択します。
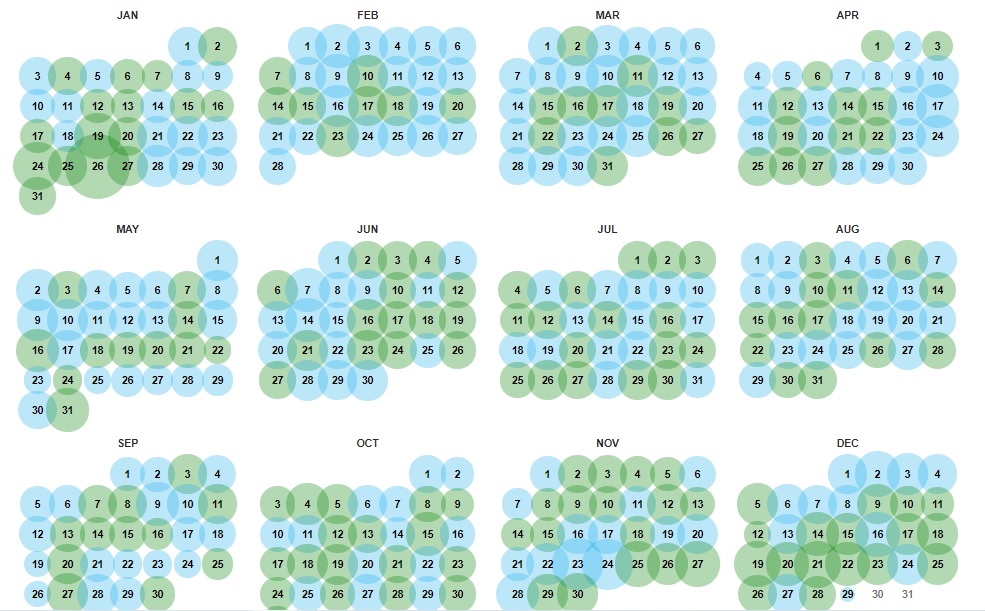
日付によって丸い円の色が違いますが、円の色によって意味に違いがあり、以下4パターンの色があります。
それぞれの色は、アーカイブした際のWEBサーバーのリクエスト結果によって異なります。
- 青色:200番台・・・リクエストに成功すると青色になります。基本的には青色が理想です。
- 緑色:300番台・・・リクエストがリダイレクトされると緑色になります。
- オレンジ色:400番台・・・クライアントエラーの場合はオレンジ色になります。
- 赤色:500番台・・・サーバーエラーの場合は赤色になります。
基本的には青色の日付を閲覧するのがベストです。
まれに赤色の日付でもアーカイブ情報を閲覧できる場合があるので、色に関わらずアーカイブされた日が複数あるなら、いくつかアーカイブ情報を確認してみるとよいでしょう。
その上で、調べたい日付を選択すると、ポップアップ表示でアーカイブ時刻の一覧が表示されるので、その中から希望のアーカイブ時刻を選択しましょう。
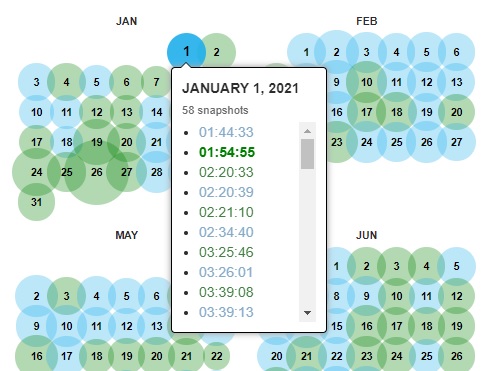
選択すると、指定した時期にアーカイブされたサイトの情報が表示されます。
Wayback Machine(ウェイバックマシン)の使い方(応用編)

基本的な使い方に関して説明しましたので、今回の項目ではWayback Machineの応用方法について解説します。
WEBサイトページをアーカイブさせる方法
Wayback Machineでアーカイブをさせる方法については、2つの方法があります。
- 自動保存
- 手動保存
自身のサイトや競合サイトをアーカイブしておけば、後から振り返ってサイトを確認する時にも役立ちますので参考にしてください。
自動保存する
Wayback Machineは基本的に自動でアーカイブをしてくれますが、必ず特定のサイトをアーカイブする、アーカイブしてくれる日時を指定、といったことができません。
そのため、運営するサイトのアーカイブ結果を調べた時に、過去のアーカイブ状況が1ヶ月に1回程アーカイブされている状況あれば、今後も同じくらいのペースでアーカイブされる可能性があります。(ただし、絶対ではありません)
サイトの履歴などを今後残しておきたいなら、確実に残せるアーカイブ方法が必要ですよね。
そこで、確実にアーカイブできる手動保存する方法を次項で紹介します。
手動保存する
Wayback MachineのTOPページに以下画像のSave Page Nowという項目があります。
その検索窓に手動保存したいURLを入力してアーカイブ保存された最新ページに移動したら対応完了です。
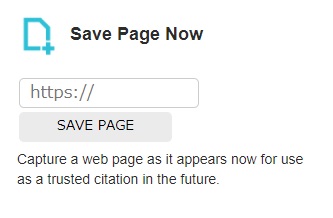
非常に簡単な方法なので、自動保存の頻度が少ない場合は定期的に手動保存をしておき、アーカイブ情報を残しておきましょう。
アーカイブされたWEBサイトページの削除方法
Wayback Machineにアーカイブされた過去の情報を削除したいという場合もありますよね。
その場合は、Wayback Machineの運営元であるInternet Archiveにアーカイブ削除依頼のメールを送る必要があります。
宛先のメールアドレスは「info@archive.org」です。
メールフォームなどはないので、直接メーラーを起動して問い合わせてください。
メール本文には削除したいURLとサイト運営者であることが証明できる内容を記載してメールを送信します。
ただし、運営元のInternet Archiveはアメリカに拠点がある団体です。
メールのやり取りは全て英文なので、注意が必要です。
サイト運営者であることを証明するには
サイト運営者であることを証明するためには、サイト運営の管理者情報ページにメールアドレスを記載して、記載したメールアドレスで削除依頼をしましょう。
削除依頼した際に、メールアドレスを記載したページURLも貼り付けてサイト運営者であることを知らせるようにします。
送ったメールアドレスと送信元のアドレスが一致している旨も、英文で送る必要がありますが、「The email address to which this email was sent can be found in the following article.(このメールの送信先となったメールアドレスは、以下の記事で確認できます。)」など、翻訳サイトで出た文章を張り付ければ大体通じるのでお試しください。
翻訳サイトはコチラ:DeepL
アクセスを制限する方法
削除まではしなくても、今後はWayback Machineにアーカイブされたくない場合もありますよね。
そのような場合は、クローラーのアクセスを制限してアーカイブさせないようしましょう。
クローラーと呼ばれるロボットがアーカイブ保存している
Wayback Machineはクローラーと呼ばれるロボットプログラムが24時間365日インターネット上を巡回し、WEBサイトのページデータをアーカイブ保存しています。
そのため、過去のページを閲覧できるのです。
つまりWayback Machineのクローラーをサイトにアクセスさせないようにすれば、物理的にアーカイブできなくなります。
クローラーのアクセス管理は「robots.txt」を使用する
クローラーのアクセス管理は、「robots.txt」と言われる命令文が記述されたファイルを使用します。
いくつかやり方があるので、それぞれのやり方については以下で解説します。
作業に慣れていない方は、必ず作業前にバックアップデータを保存しておくようにしましょう。
ドメインでアクセス制限
- 「robots.txt」に以下の命令文を記載してテキストファイルを保存
- サイトデータを保存しているデータサーバー内の一番上の階層であるディレクトリ(ルートディレクトリ)の中にアップロードして保存
|
1 2 |
User-agent: ia_archiver Disallow: / |
この対応で、ドメイン単位でWayback Machineのクローラーアクセスを制限できます。
ディレクトリでアクセス制限
先ほどは、ドメイン単位でしたが、次はディレクトリ単位でアクセスを制限する方法を紹介します。
- 「Disallow: /」以下にディレクトリ名を記載
- ルートディレクトリの中に「robots.txt」ファイルを保存
命令文は以下になります。
|
1 2 |
User-agent: ia_archiver Disallow: /ディレクトリ名/ |
制限したいディレクトリが複数ある場合は、以下のように制限したいディレクトリを追加していくイメージです。
|
1 2 3 4 |
User-agent: ia_archiver Disallow: /ディレクトリ名A/ Disallow: /ディレクトリ名B/ Disallow: /ディレクトリ名C/ |
指定ページでアクセス制限
最後に指定したページでアクセス制限する方法です。
- 以下の命令文を「robots.txt」ファイルに記載
- ルートディレクトリの中に保存
|
1 2 |
User-agent: ia_archiver Disallow: /ディレクトリ名/ページファイル名 |
ディレクトリ名が「seo」でページファイル名が「waybackmachine.html」の場合は以下のようになります。
|
1 2 |
User-agent: ia_archiver Disallow: /seo/waybackmachine.html |
Wayback Machine(ウェイバックマシン)の活用方法

Wayback Machineを使った活用方法を紹介します。
運営しているサイトの過去のアーカイブ情報を閲覧するだけでなく、その他の使い方もあるので是非参考にしてみてください。
拡張機能
Wayback MachineにはChromeやFirefoxで使用できる拡張機能が用意されています。
Chromeの拡張機能はこちら
https://chrome.google.com/webstore/detail/wayback-machine/fpnmgdkabkmnadcjpehmlllkndpkmiak?hl=ja
毎回Wayback Machineのサイトにアクセスしなくても拡張機能のボタンをクリックするだけで済むので、頻繁にWayback Machineを使用する方にはおすすめです。

SEO対策
公開した記事の順位に応じてリライト(コンテンツ内容の追加や削除、書き換え等をすること)をする機会も多いですよね。
リライトによって順位が改善する場合もあれば、順位低下になってしまう場合もあります。
Googleのアルゴリズムはその時のトレンドであったり、重視する評価ポイントも日々変化しています。
そのため、何が要因で順位が上位化したのかや、順位が低下したのかがわかりにくいという状況は日常茶飯事です。
そうした状況下でも仮説検証を繰り返しSEO対策をしていく必要がありますが、そうした際に、Wayback Machineを使い過去のコンテンツ内容と比較することで「上位化されていた時は○○の要素が含まれていたけれど、順位が低下した時は○○の要素が削除されてしまっていた」といったような分析をすることが可能です。
Googleの検索エンジンはユーザーの利便性が高いサイトを上位化するようなアルゴリズムになっているため、状況に合わせて文字を追加するだけのリライトではなく、画像や動画の追加といったテキスト以外のリライトもより重要な要素になっています。
競合サイト調査
上記のSEO対策と同様に、競合サイトの過去コンテンツと現コンテンツの比較をすることで、どんな対策をしたのかとなど把握できます。
SEOの視点だけに限らず、競合サイトのLP(ランディングページ:ユーザーが初めてアクセスするページ)を遡って確認していけば、どういった改善をおこなっているかといったマーケティング要素の視点からも競合サイトの調査ができます。
例えば、競合サイトでは購入ボタンのサイズやデザインがアーカイブデータ毎に変わっている場合はCVR(Conversion Rate:コンバージョン率)の改善をしている可能性があります。
あくまでも一例ではありますが、こういった使い方もWayback Machineでは可能になります。
Wayback Machineの安全性
Wayback Machineはとても便利なサービスですが、しかしWayback Machineの安全性も気になるところです。
結論から言うと、Wayback Machineは危険なく利用できるサービスです。
最初にお伝えしたように、運営元のInternet Archiveはアメリカのサンフランシスコで1996年に発足した非営利団体です。
Internet Archiveの公式サイト(https://archive.org/)には、以下の文言が記載されています。
Internet Archive is a non-profit library of millions of free books, movies, software, music, websites, and more.
翻訳すると、「インターネット・アーカイブは、何百万もの無料の書籍、映画、ソフトウェア、音楽、ウェブサイトなどを集めた非営利の図書館です。」とのことで、営利的な活動のない団体というわけですね。
広告もなく、会員登録なども必要ないので、総合的に見ても安全性の高いサービスと言えるでしょう。
ウイルス対策ソフトを入れていない人は注意
Wayback Machineは安全性の高いサービスと言えますが、無数のサイトを保存しているとだけあって、その中には詐欺サイトなども含まれる危険性は考えておいたほうが良いですね。
とはいえウイルス対策ソフトを入れておけば、特に問題ありません。
これまでのウイルスサイトの歴史について興味がある方は、Internet Archiveのサービス「The Malware Museum」でこれまでのマルウェアウイルスがまとめられているので覗いてみると良いでしょう。
マルウェア博物館はコチラ:The Malware Museum
Wayback MachineでTwitterのタイムラインやYouTubeの動画は保存できる?
Wayback MachineでTwitterのタイムラインを保存できます。
しかしYoutubeの動画はWayback Machineではなく、Movie Archiveのほうで保存されているようですが、保存件数は多くありません。
YouTubeのホーム画面は画面として保存されているので、どのような動画を出していたのかなどの確認はできますね。
ただし、それぞれ自動保存だと保存しきれていない可能性が高いため、履歴を確実に確認したい場合は手動保存をおすすめします。
Twitterのタイムラインは自動保存頻度が低い
Wayback Machineについて調べてみると、Twitterも保存されていることは記載されている記事が多いのですが、実際に見られるかどうかについて触れている記事は少ないです。
そこで頻繁にツイートしている個人アカウントで調べてみたところ、以下のような結果になりました。

保存されてはいますが、頻度がとても低いですね。
実際に保存されているかも確認すると、過去のタイムラインが表示されたので、Twitterを保存すること自体は問題ないようです。
ログインを求められることがある
自分以外のアカウントで検索した場合、ログインを求められることがありますが、ログイン画面はログイン画面を記録したに過ぎないため、IDやパスワードを入力してもログインできません。
ログイン画面が表示された場合は、ページを戻りましょう。
Twitterのツイート単体で見る方法

URLで検索窓の下に、上の画像のような文字列が並んでいますので、「URLs」をクリックしてください。
するとツイート単体で見られるようになります。
タイムラインが保存されていなくても、ツイート単体は保存されている場合がありますので、確認してみると良いでしょう。
「MIME Type」が「application/json」のものは、文字の羅列が出てくるだけなので、ツイートを見たいのであれば「text/html」のものを選択して確認しましょう。
YouTubeも保存頻度は低い
YouTubeもWayback Machineで保存できます。
試しに日本の人気YouTuberのURLで検索してみたところ、以下のように表示されました。
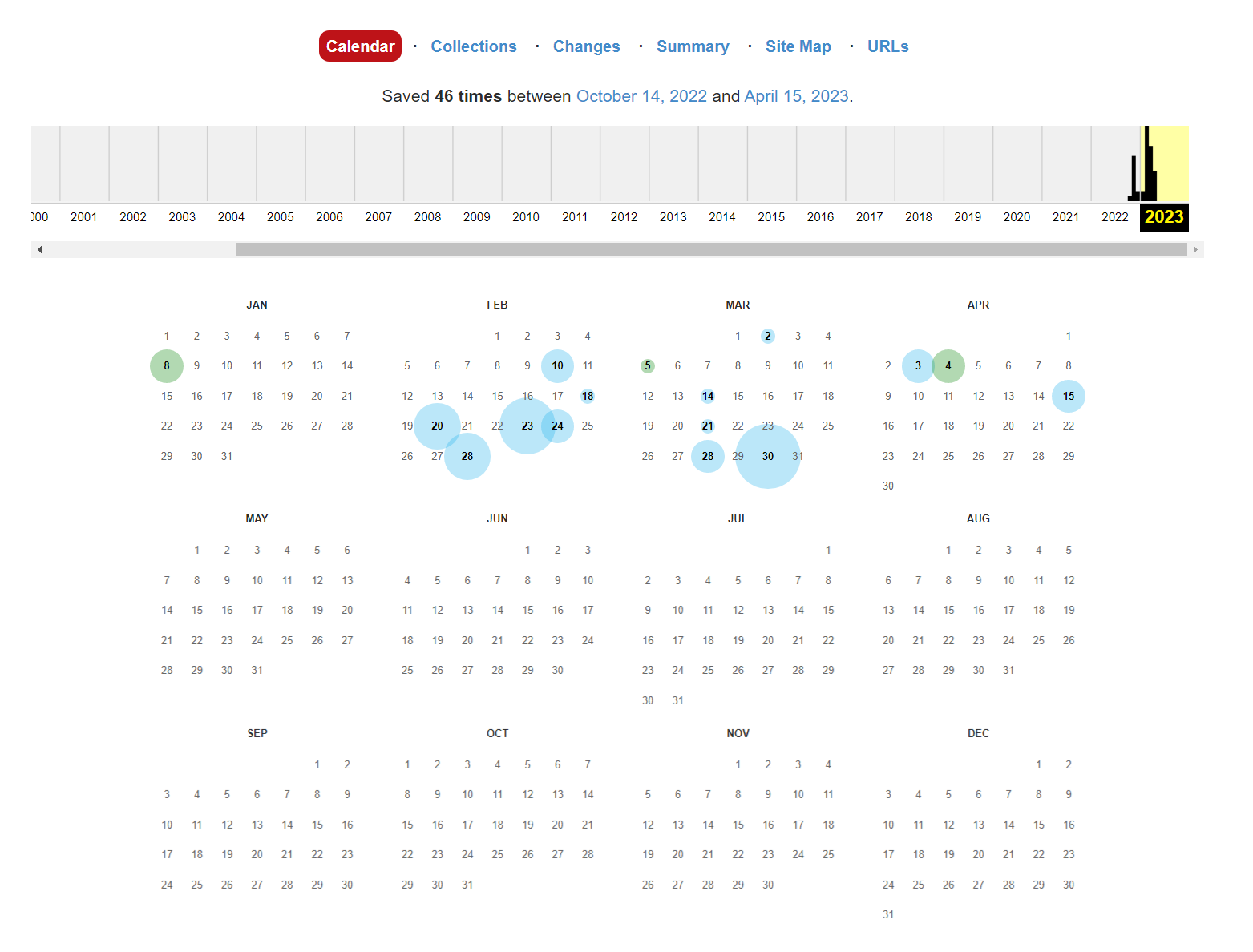
人気YouTuberでも自動保存は2022年10月から2023年4月までで46回なので、保存頻度は低いですね。
実際にどのように保存されているか見てみると、YouTubeチャンネルのホーム画面が表示されました。
動画自体をクリックすると、以下のように表示されるので、動画自体は見られないと考えたほうが良いでしょう。
Twitterの鍵垢でも保存できる?
Twitterの鍵アカウント(鍵垢)の場合、第三者が自由に見られないので保存はできません。
もし鍵アカウントで保存したい場合は、一度鍵を開けてから手動保存して、また鍵をかけるというような方法をとると良いですね。
第三者の鍵アカウントを保存したい場合も同様で、保存したいタイミングで開けてもらう必要があります。
Wayback Machineの注意点
Wayback Machineはとても便利なサービスですが、以下の注意点があります。
- IDやパスワードが必要なページは保存できない
- 表示に時間がかかる
- 表示させたくて1分間に15回以上表示リクエストするとエラーになる
- 必ずほしいデータがあるわけではない
どういうことなのか、分けて解説します。
注意点1.IDやパスワードが必要なページは保存できない
個人情報や、クローズドなウェブサイト・ホームページの場合、IDやパスワードがないと中身を見られませんよね。
そのようなサイトは、公開されているとは言えないので保存できません。
クローズドなサイトを画像として保存しておきたい場合は、魚拓サービスなどを利用すると良いでしょう。
注意点2.表示に時間がかかる
Wayback Machineは、膨大なデータを持つサービスです。
そのため、サイト自体の動作速度も決して速いとは言えません。
むしろ遅いくらいなので、利用する際はゆっくり待つことを前提にすると良いでしょう。
注意点3.表示させたくて1分間に15回以上表示リクエストするとエラーになる
Wayback Machineは表示に時間がかかるサービスですが、だからといって1分間に15回以上表示リクエストを行うとエラーになり、また始めからやり直しになりかねません。
急かせば急かすほど逆効果なので気を付けましょう。
注意点4.必ずほしいデータがあるわけではない
Wayback Machineには膨大なデータがありますが、しかし全てのウェブサイト・ホームページが必ず保存されている保証はありません。
自動保存も頻度が高いわけではないので、今後データが必要になるシーンがありそうなのであれば、手動保存を定期的に行うことも検討すると良いでしょう。
Wayback Machineでサイトや動画・画像が見られない!原因は?
Wayback Machineでサイトや動画・画像が見られない時は以下の原因があげられます。
- サイトの運営歴が短い
- サイト情報が運営者により削除されている
- 動画はそもそもWayback Machineのサービスには含まれない
- 画像はロードされきっていない場合がある
どのような原因なのか、分けて解説します。
サイトの運営歴が短い
サイトの運営歴が短い場合、自動保存するためにクローラーが訪れていない可能性があります。
クローラーが訪れないうちにサイトが閉鎖されてしまうと、保存自体されていないのでデータとしても残りません。
同じように、Twitterなどのアカウントでも運用歴が短い・鍵が開いていた期間が短いといった場合は表示されない可能性が高くなります。
サイトの情報が運営者により削除されている
Wayback Machineは運営者が削除依頼のメールを送ると、データを削除してもらえます。
そのため、サイトの運営者が削除依頼メールを送った場合はデータとして残っていません。
この場合、手動保存をしてもサイト運営者により再度削除依頼が出る可能性があるので、今後長くデータを残すのは難しいでしょう。
魚拓サービスなどを利用し、個人的にデータを持っておくほうが確実です。
動画はそもそもWayback Machineのサービスには含まれない
動画はそもそもWayback Machineのサービスには含まれないため、動画をWayback Machineで見ようとしないほうが良いでしょう。
もし動画を見たい場合は、Wayback Machineではなく、Movie Archiveを利用することをおすすめします。
画像はロードされきっていない場合がある
Wayback Machineはウェブサイト・ホームページを保存してくれるサービスですが、画像が多い場合は表示されないことも多いようです。
または、画像のみロードされきっていない場合もあります。
Wayback Machineは動作が遅いサービスなので、画像が多い場合などはゆっくり待つことも必要です。
Wayback Machineとは?まとめ

Wayback Machineは過去のアーカイブ保存されたサイト情報を遡って無料で閲覧できます。
運営しているサイトだけでなく、競合サイトの情報を閲覧することもできるので、競合サイト調査にもおすすめのツールです。
使い方や活用方法も多岐にわたるので、自身の状況に合わせて最適な使い方を見つけてみるのもよいでしょう。

![]()
![]()


